
在 v2ex 社区看到有人提问怎么把十万个电话号码排出出现次数最多的十个电话号码,我看到这个问题的时候第一时间想到的是将十万个电话号码读出来放到 Redis 中,之后做一个动态计数器,使用 foreach 函数对这个电话号码进行遍历,以电话号码为索引 key,计数器 value 进行自增,最后求出最多的电话号码,这样最后时间复杂度为 O(n),不是一个好的解决方案,之后我看到评论区,有人提出使用归并排序,原理是一样的,不过可以将十万个电话号码平均分成十组,之后每组查找电话号码最多的十个号码,最后将十组最多的号码取出来再次进行相加排序,最后得到的最多的十个号码就是十万个电话号码中出现次数最多的号码。
看到这个问题,我不由得想到了我刚来去某浪面试的时候,面试官问我的问题和这个问题基本一致,不过是数的基数比较大,当时的我解决方案和现在我想的一样,很遗憾,没有结果,不得不说技术还是太菜了。之后我查了一下归并排序是采用的分治法的思想,即将一个问题分为若干个小的子问题进行解决,最后问题的解就是子问题结果的解的合并,接下来就详细的了解一下归并排序吧!
基本思想
归并排序 mergesort,是创建在归并操作上的一种有效的排序算法,效率为O(nlogn)。1945年由约翰·冯·诺伊曼首次提出。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用,且各层分治递归可以同时进行。
采用分治思想,将一个问题拆分为若干个问题,之后将若干个问题解决,最后将若干个结果进行合并,即最终结果。
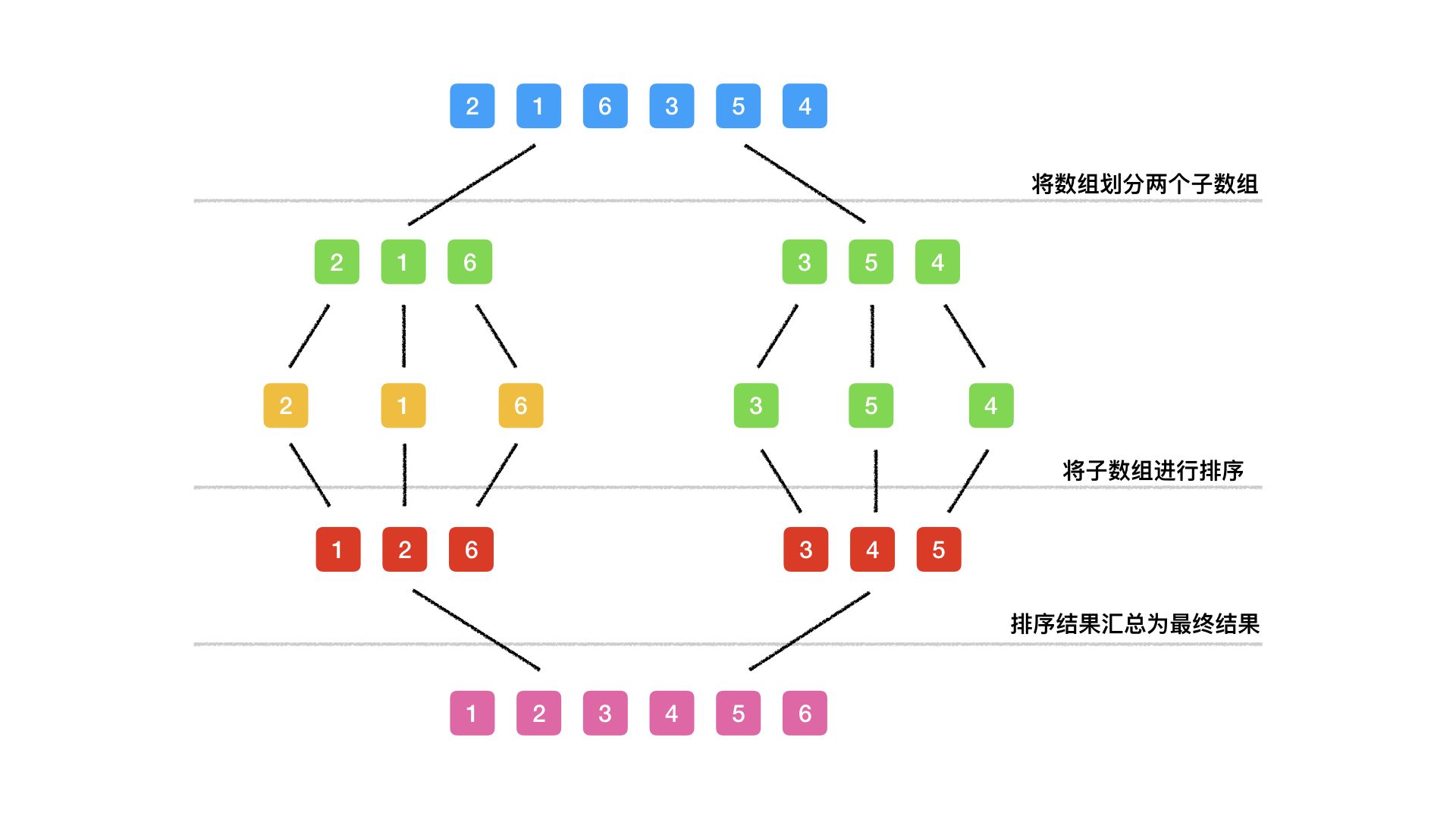
分治合并
在合并结果阶段,可以看到两个子结果的求解数组为[1, 2, 6] 和 [3, 4, 5],将子数组合并排序为 [1, 2, 3, 4, 5, 6]。
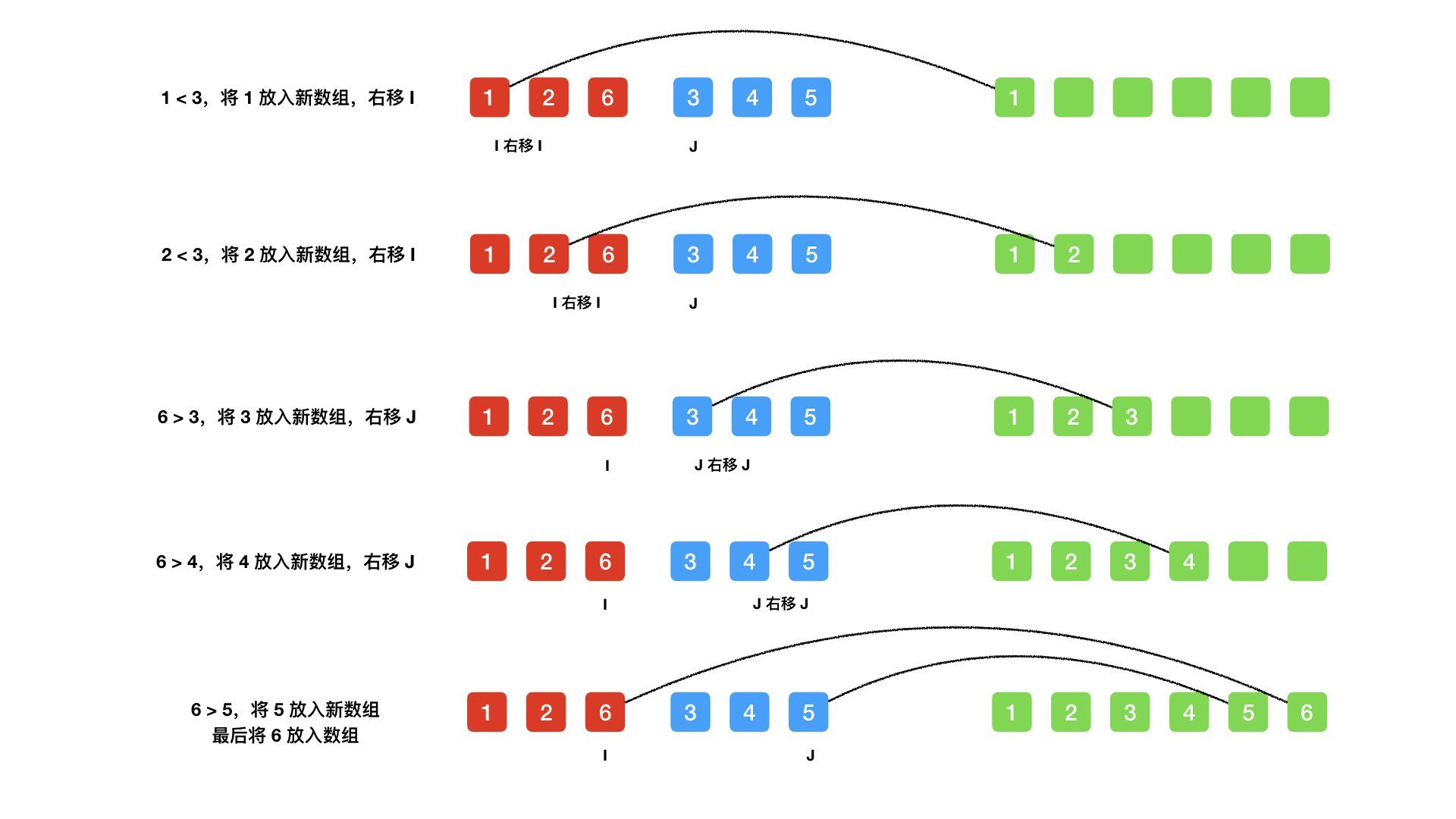
算法实现
在这里使用的是 PHP,其实算法思想一致,用啥语言都可以实现,不过一种语言有一种语言的语法
| |
输出结果:
| |
结论
归并排序比较占用内存,但却是一种效率高且稳定的算法。归并排序的最好,最坏,平均时间复杂度均为O(nlogn)。